PriceScraper
07/06/2025
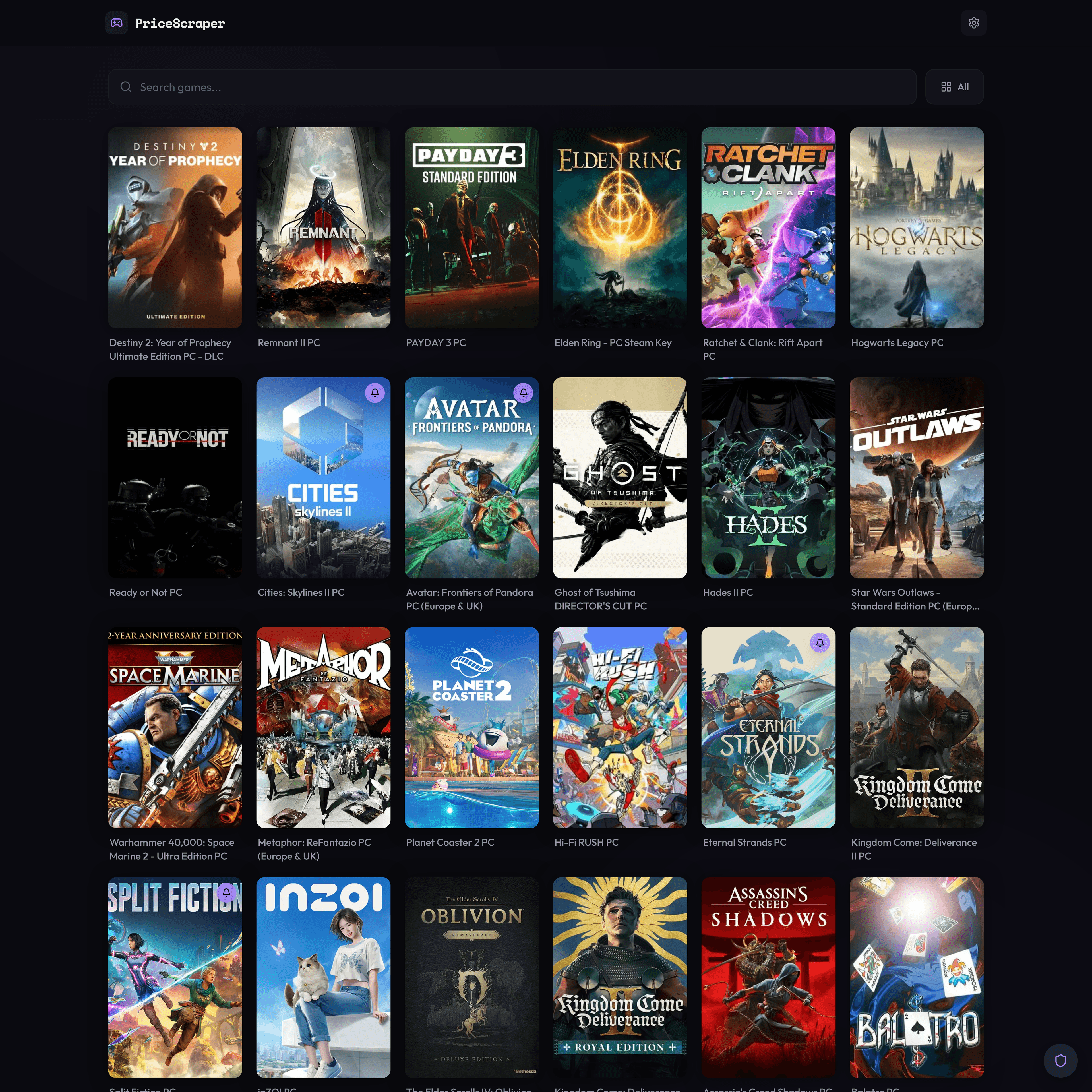
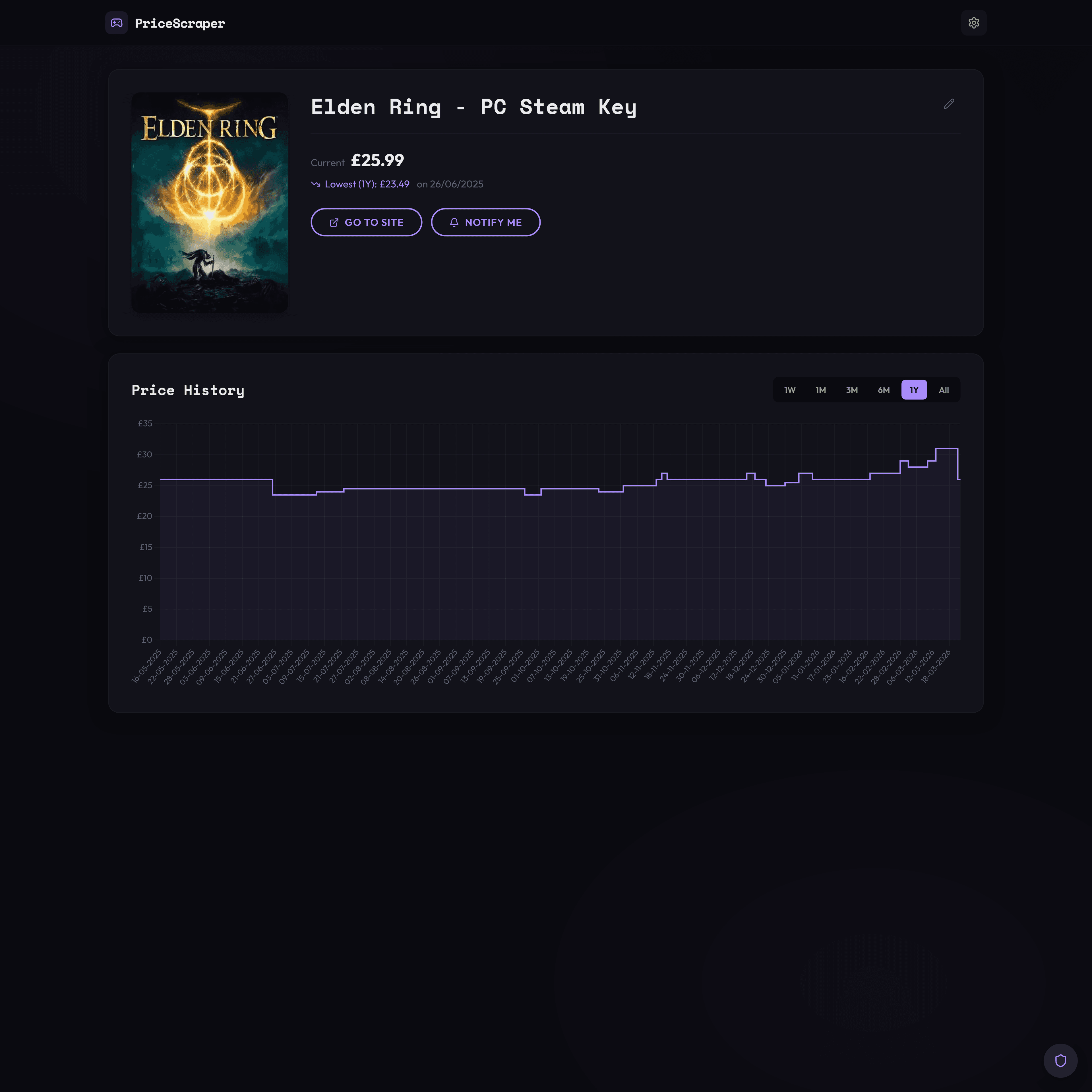
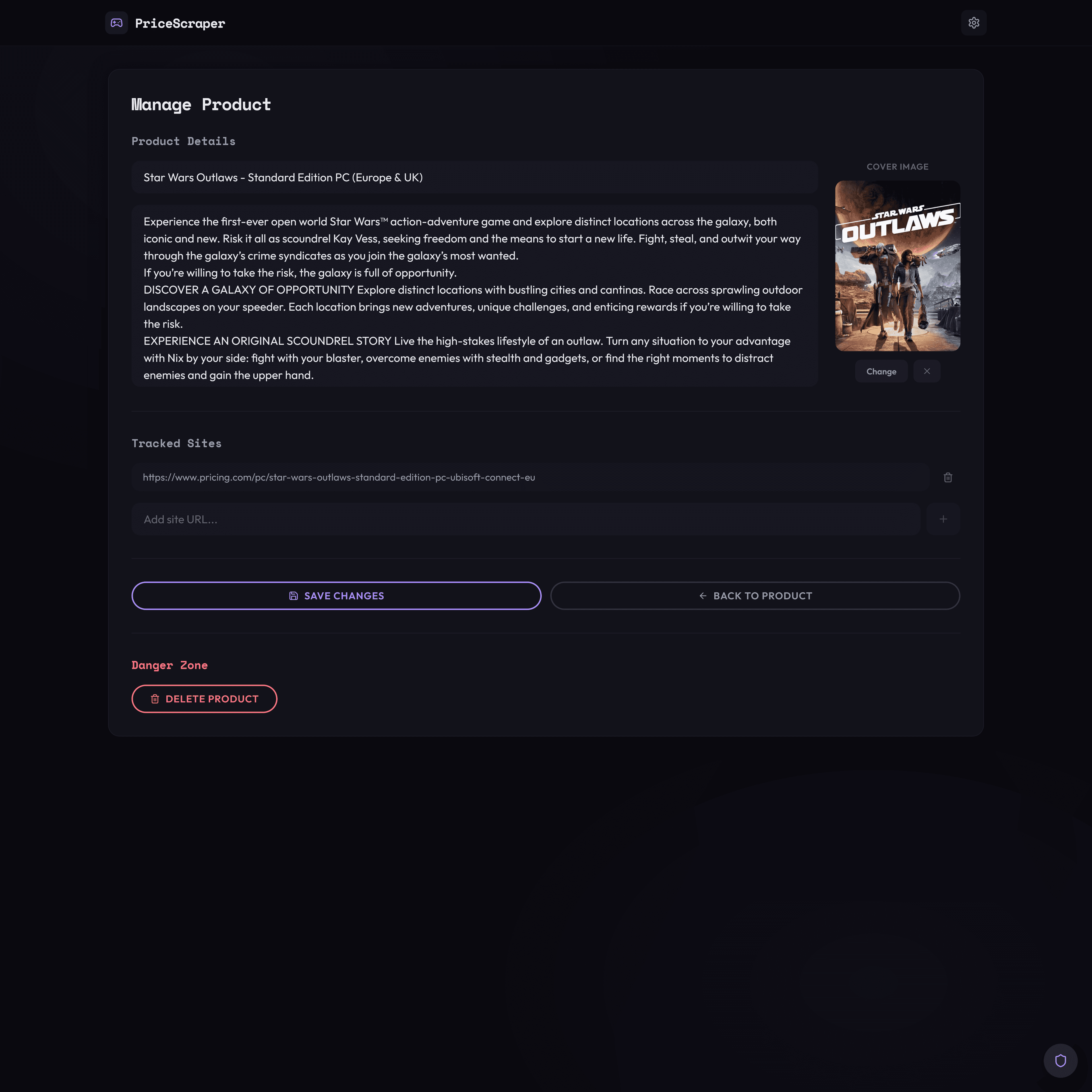
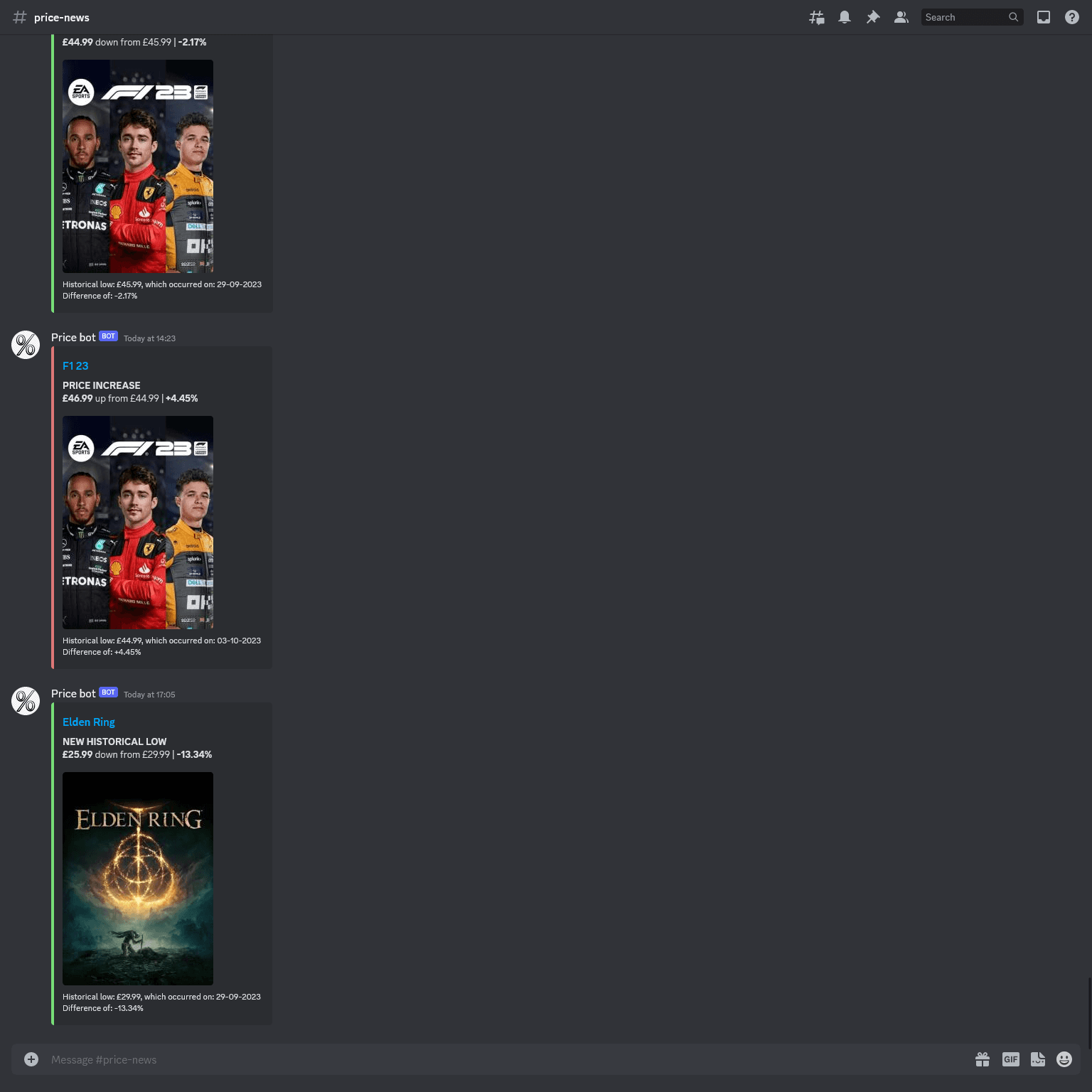
Home page
I originally created PriceScraper after noticing that third party websites I would commonly purchase game prices would change their prices, sometimes multiple times in a week. Since most third-party websites don't track this history, I wanted a way to monitor price trends over time and receive real-time notifications when a game's price changed.
The initial version of PriceScraper was a simple command-line tool written in Python. It scraped price data from specific storefronts and sent updates via Discord webhooks whenever prices changed. This worked well for tracking a small number of games.
However, adding new games was tedious: every game had to be manually configured via the CLI, including details like artwork and metadata. It quickly became clear that a more user-friendly interface was needed.
To improve usability, I built a web interface using React for the front-end and Express for the back-end. This was my first full-stack web application, and it involved a steep learning curve as I learned how to:
- Design RESTful APIs
- Handle asynchronous data fetching
- Manage client-side state and routing in React
This setup made it easier to view tracked games and manage them via the browser. However, the backend still relied on the original Python script to handle scraping.
Over time, a few major issues emerged:
- The Python script had poor error handling and would occasionally crash.
- It had no recovery mechanism, so I had to manually log into the server to restart it.
These issues led me to rethink the architecture from the ground up.
I decided to rewrite the scraping logic in Rust to improve performance, reliability, and error handling. In the new version:
- The scraper runs as a standalone Rust binary that performs its task and exits.
- The Express backend is now responsible for triggering the scraper on a regular schedule.
- I improved the error handling to ensure crashes are logged clearly, and failures don't silently break the system.
This change not only improved stability, but also gave me hands-on experience with systems programming and asynchronous networking in Rust.
Previously, every game had to be added manually—including uploading the game artwork and typing in details like title and price.
With the Rust rewrite, I added a game import feature: now, users can paste a link to a supported storefront, and the scraper will automatically extract the game's metadata and artwork, then store it in the database. This drastically reduced the friction in adding new games.
With the core system stable and the Rust-based scraper working reliably, I turned my attention to recreating the web interface using Next.js. This framework change also provided an opportunity to improve the user experience, with a brand new modernised design and feel. Alongside this migration, I also made security improvements to the Express server. This phase was less about adding new features and more about modernising the stack.